
在MySQL页中我们介绍了数据页(即索引页)的结构,并且页了解了页内查询的整体流程,数据在单个页中查询会很快,但是现实中数据量是远远大于一个页所能承载的范围的,所以这就涉及到了数据的页间查询了,没有很好的页间信息支撑查询,只能通过页遍历来查找所需数据,这是非常耗时的。
所以InnoDB的设计者设计了索引结构来进行数据的页间查找,下面会详细说明索引结构的构建过程、构建成功后索引是如何进行数据查找的以及为什么能提高页间数据查找的效率。
此时页结构是这样的:
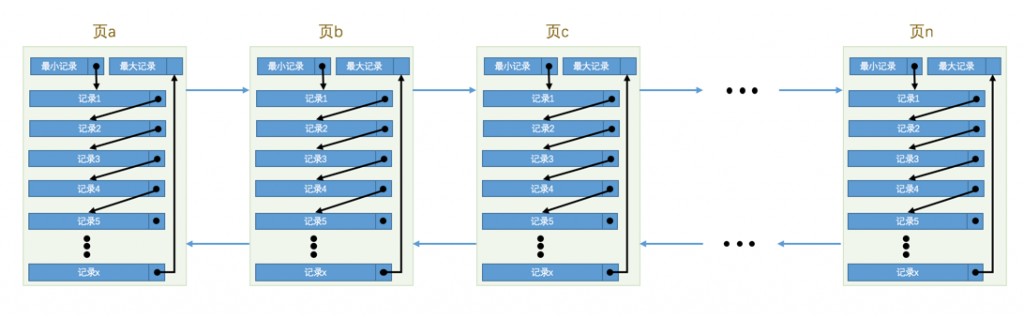
我们以精确查找为例(即搜索条件为列明=xxx),多页索引流程大体是:
- 找到记录所在的页。
- 页内查找具体的记录。
因为页内查找流程在页的数据页中介绍过,所以我们现在主要问题是如何在众多页中找到记录所在的页。
一个简单的索引方案
通过建立一个页目录的方式来提高查找的效率,并按下面步骤一步一步来实现:
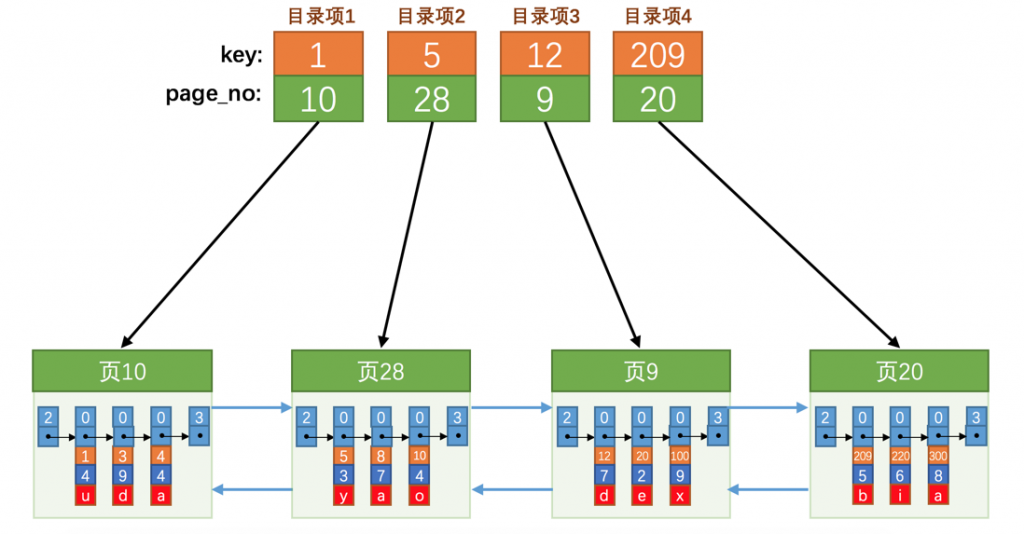
- 规定下一个页所有记录的主键值都要大于上一个页中所有记录的主键值。

- 给所有页建立一个目录。
- 每个页对应一个目录项。每个目录项相当于一条用户记录,只不过列是指定的,分别为:
- 页号。对应于每个页的地址。
- key值。用于存储指定数据页的最小索引值,下图中索引key为主键,此时目录项1就是存储的页10的最小记录主键值即1。
- 每个页对应一个目录项。每个目录项相当于一条用户记录,只不过列是指定的,分别为:
- 建立完页目录后,InnoDB设计者决定采用页作为页目录的载体。并用行记录的记录头中的record_type加以区分(
0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录)。
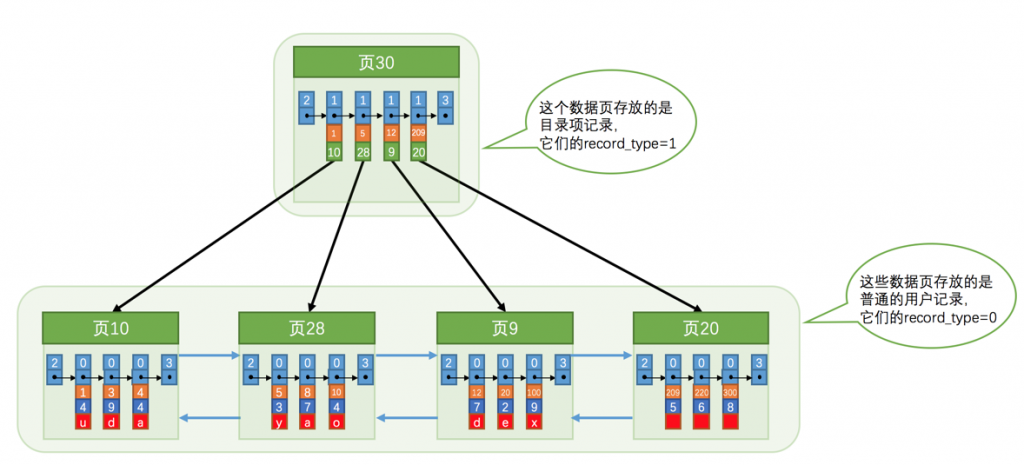
构建完页目录结构后,我们得到了上图这样的页间结构,上图中页数据只有12条,但真实数据量并没有这么少,我们现假设每页中最多能存储3条用户数据(或者最多4条目录项),也就是说一页页目录只能存储12条数据,那大于12条数据之后页目录的数量肯定大于1。
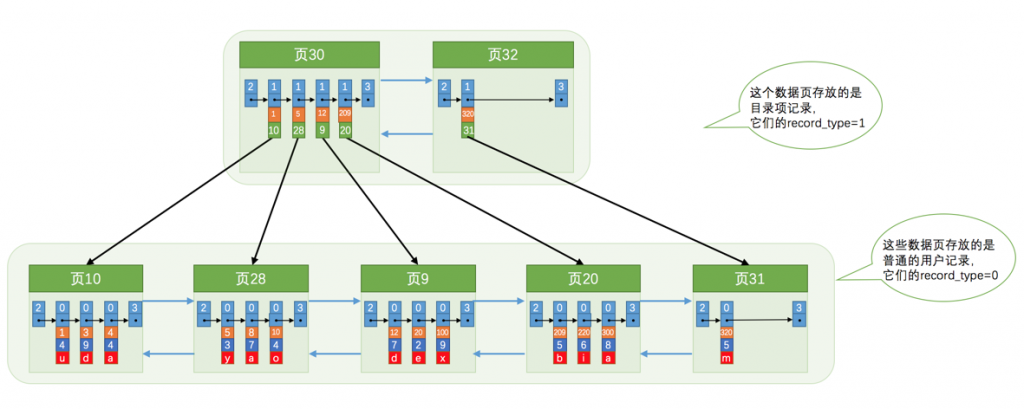
此时如果为了查找某条数据,我们是否需要遍历页目录呢,答案是不会,我们可以依葫芦画瓢建立页目录的页目录,并根据更高层的目录项进行索引。
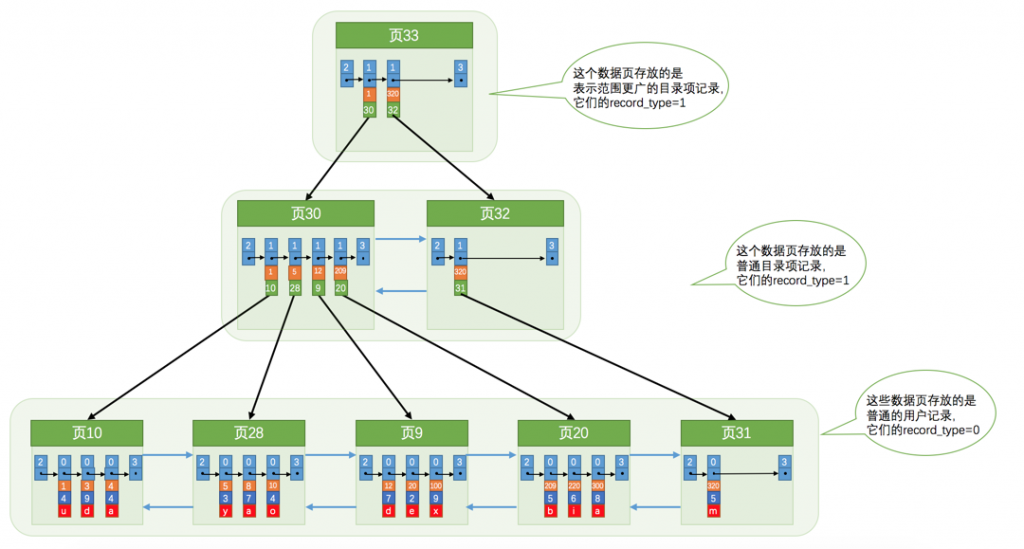
以此类推,这就形成了我们熟知的B+树索引。根据层数的增加我们能存储的数据量也在增加,基于刚才的假设2层就能存4X3条记录,3层就能存4X4X3条记录,4层就能存4X4X4X3条记录,依次类推,所以我们并不需要担心该B+树结构存储容量的问题。
最后查询流程我们依然可以遵循页内查询的方法:
- 根据二分法查找记录所在页。
- 页内精确查找对应数据。

发表回复